前言
由于最近smms不太稳定,有时候会访问慢、加载慢,故决定迁移图床,但是smms没有提供批量操作的功能,故从开发者文档寻找突破,采用爬虫爬取。
coding
开发者文档,从开发者文档我们拿到了请求头部 headers 、url以及返回的数据,这对于我们编写程序就很容易了。
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| import requests
api_token = "****"
api_url = "https://sm.ms/api/v2/upload_history?page=1"
headers = {
"Authorization": f"{api_token}",
"Content-Type": "multipart/form-data"
}
response = requests.get(api_url, headers=headers)
data = response.json()
print(data)
if "data" in data:
for image_info in data["data"]:
img_url = image_info["url"]
img_name = img_url.split("/")[-1]
img_data = requests.get(img_url).content
with open(img_name, "wb") as img_file:
img_file.write(img_data)
print(f"Downloaded: {img_name}")
else:
print("API request failed:", data)
|
这里因为我的图床只有一页,故page就没有用循环来处理了,你可以尝试修改为2看返回的数据是否为空来决定你的page2是否有图
可以看到每一页有100张图,我这里就懒得写循环了~~!
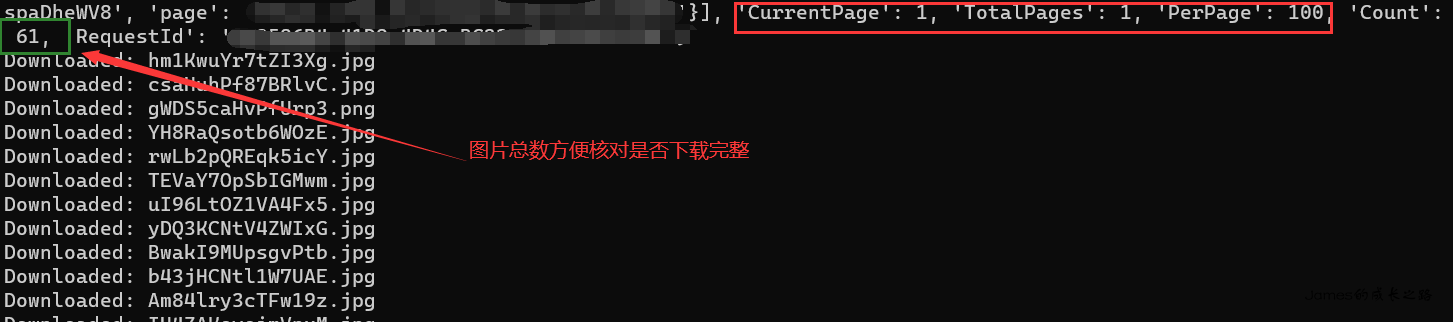
运行结果
该封面图片由Roshalys在Pixabay上发布





