AI System - 介绍
AI 的历史与现状
AI 的领域应用
人工智能正在日益渗透到所有的技术领域,而深度学习是目前人工智能中最活跃的分支。
CV 领域应用
“计算机视觉,尤其是图像识别,是深度学习能力的一些最早重要演示的主题。”
- “自动驾驶汽车使用深度学习来识别和跟踪…车辆、行人和其他物体。”
- “搜索引擎…根据图像查询提供准确且相关的搜索结果。”
- “机场和政府大楼使用面部识别来筛查乘客和员工。”
- “已从…图片分类、目标检测和物体分割,逐渐过渡到…二维甚至三维的图片生成。”
NLP 领域应用
“深度学习与 NLP 有着密切的联系…研究如何让计算机更好地理解和处理自然语言。”
- “词向量表示…更好地捕捉词语的语义信息。”
- “使用 CNN/RNN 等模型,对文本进行分类或情感分析。”
- “机器翻译…利用大量双语语料库进行训练,从而实现高质量的机器翻译。”
- “最新的进展已经能够使用语言大模型 LLM 实现人机对话、摘要自动生成和信息检索等功能。”
Audio 领域应用
“智能音频处理…实现音频信号的分析、识别和合成等任务。”
- “音频分类、音频分割和音频降噪…通过训练神经网络模型。”
- “语音识别…将语音信号转化为文本信息。”
- “音频合成…生成逼真的语音合成结果…音乐合成。”
- “端到端的音频处理…简化处理流程并提高效率。”
- “跨模态音频处理…与图像或文本信息进行联合处理。”
AI 场景与行业应用
“人工智能逐渐在互联网、制造业、医疗、金融等不同行业和场景涌现大范围的应用。”
- 金融:“信用评估、风险管理、反欺诈…提高业务效率,降低风险。”
- 医疗:“疾病诊断、药物研发、病历管理…提高疾病诊断准确率,降低…成本。”
- 教育:“个性化教育、智能辅导、智能评估…提高学习效果,降低教育成本。”
- 互联网:“文本向量化…提升检索质量;点击率预测…获取更高的利润。”
- 自动驾驶:“更准确地识别道路上的物体…更安全地执行驾驶决策。”
“…在人工智能基础设施和系统上投入…提升…生产效率…再通过业务场景反哺,获取更多的数据…驱动人工智能系统与工具链的创新与发展。”
AI 基本理论奠定
“其当前基于的核心理论…在这波浪潮开始前已经基本奠定,并经历了多次的起起伏伏。”
萌芽兴奋期(约 1950s)
- 1943:“McCulloch 和 Pitts…创造了一种神经网络计算模型。”
- 1950:“图灵测试…提出。”
- 1957:“Rosenblatt 发明感知机(Perceptron)…以矩阵乘加运算为主。”
- 1960:“Adaline/Madaline…尝试…多层感知器网络。”
- 1969:“单层感知器无法解决…异或问题…计算能力不足…研究停滞。”
- 1974:“Werbos…误差反向传播…训练多层神经网络成为可能。”
蓬勃发展期(约 1980s)
-
1986:“‘Deep Learning’ 一词…引入机器学习社区。”
-
1989:“LeCun 提出 LeNet…卷积神经网络的重要负载。”
-
1990s:“统计学习登场…SVM 成为主流。”
-
2006:“Hinton 等…无监督预训练 + 监督微调…深度信念网络。”
-
2009–2011:ImageNet 项目建立与发布,众包标注体系完善。
突破驱动繁荣期(约 2010s)
- 2011:“微软…会话语音转录…相对错误率降低 22–33%…依赖分布式 GPU 训练。”
- 2012(1月):“谷歌…16,000 处理器…无监督学习…从视频静帧学会识别‘猫’。”
- 2012(9月):“AlexNet…赢得 ImageNet 竞赛…ReLU、Dropout、LRN…2 块 GTX 580 加速。”
“以 ImageNet 等公开…数据集…驱动…CNN、RNN、Transformer、GNN…发展和创新…模型作为上层应用负载,是驱动系统演化的驱动力之一。”
大模型带来新机遇(约 2020s)
- 2021:“《On the Opportunities and Risk of Foundation Models》…称为大模型。”
- “包括 BERT、GPT-3、CLIP、DALL·E 等…涉及…训练、微调、评价、加速、数据、安全、对齐…仍处于快速发展。”
小结与思考
- “需要深刻理解上层 AI 计算应用负载特点,历史和趋势,才能找到系统设计的真实需求问题和优化机会。”
- “AI 在 CV、NLP、Audio…及金融、医疗、教育等行业有广泛应用,其模型结构和部署需求不断演变。”
- “基本理论…经历了…萌芽→蓬勃→突破驱动繁荣…受硬件算力和模型创新推动…近年来,大模型出现带来新机遇。”
AI 发展驱动力
“AI 技术早在此之前已在工业界广泛部署(排序、检索、推荐等)。”
“机器学习是实现 AI 的一种方法,深度学习是实现机器学习的技术,神经网络是深度学习的具体实现形态。”
后续以“AI”代指神经网络这一具体实现形态。
AI 学习方法
“先理解 AI 的原理与特点,再谈系统设计。”
-
确定模型输入输出
“输入样本(Sample),输出标签(Label)……如输入图片,输出类别。” -
设计与开发模型
“线段代表权重,圆圈代表计算; 为可学习参数(权重)。” -
训练(Training)
“本质:最小化 Loss。计算梯度 ,用优化算法(梯度下降)更新权重与偏置。”- 3.1 前向传播:完成各层矩阵计算与 Loss 计算。
- 3.2 反向传播:逐层求梯度。
- 3.3 梯度更新:按学习率更新权重。
“不断迭代直至收敛或达到终止条件。”
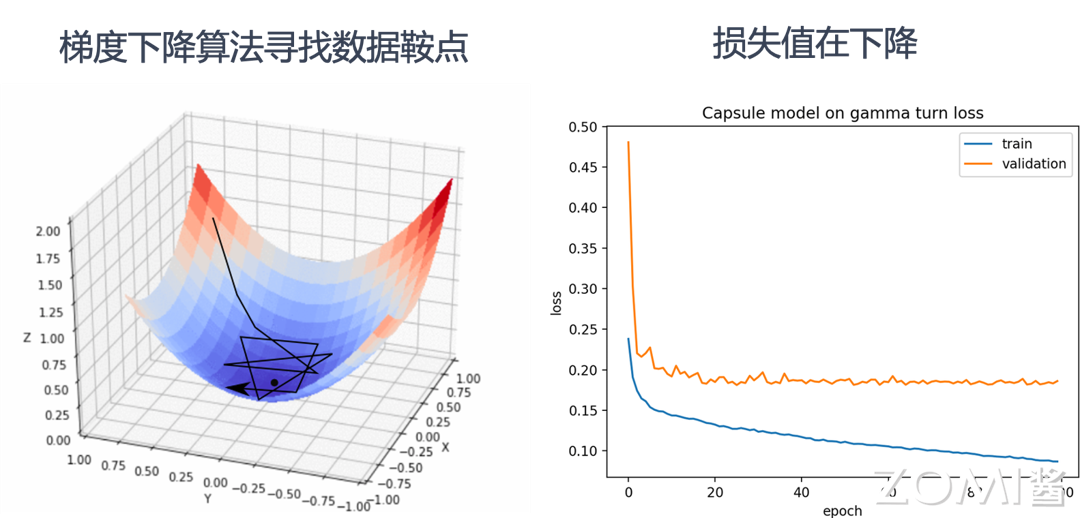
-
推理(Inference)
“仅执行前向传播:用训练好的模型,对新输入给出预测结果。”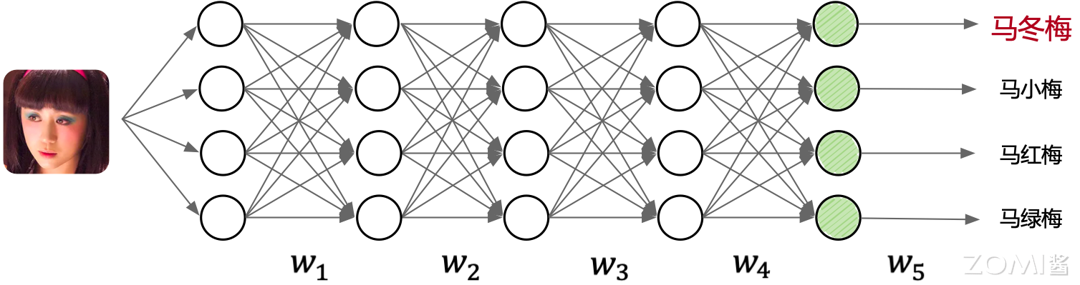
“AI 系统围绕训练与推理的全生命周期:开发体验、极致性能、安全、规模化、云上多租户、发挥新硬件特性。”
AI 算法现状
代表性结构(也是系统评测常用基准):
- CNN:卷积/池化/全连接组合,“在 CV 领域应用广泛”。
- RNN/LSTM:时序数据(NLP/语音/监控)。
- GNN:图结构学习(聚类/分类/预测/分割/生成)。
- GAN:生成式,对抗训练“生成更真实的新数据”。
- 扩散模型(Diffusion):潜变量 + 变分估计,“学习逆扩散过程进行去噪/生成”。
- 混合结构(Ensemble):组合多类网络以应对复杂任务(如 OCR)。
新趋势:
- 更大的模型:Transformer/LLM(BERT、GPT、LLaMA),“层数与参数激增 → 内存管理/分布式训练/集群设计挑战。”
- 更灵活的结构:图/树等复杂数据结构 → 新算子与框架。
- 更稀疏的结构:MoE/Pathways,“运行时更动态与稀疏,驱动 JIT 与更高效调度。”
- 更大搜索空间:HPO/NAS/AutoML,“多作业编排与调度 需求增强。”
- 更多样训练方式:扩散、深度强化学习,“训练/推理/数据处理 混合部署与协同优化。”
AI 系统的出现
“三大因素:大数据、超大规模算力、算法突破。”
大规模数据驱动
- “互联网/移动互联网沉淀海量数据,形成数据湖与平台,推动深度学习落地与迭代。”
- 典型来源:搜索引擎(ImageNet/COCO、Wikipedia)与移动应用(电商/社区产生的大规模推荐与广告数据)。
- “数据的质与量决定模型天花板;规模从 MNIST(6 万/10 类)→ ImageNet(1600 万/1000 类)→ Web 级数据。”
对系统的影响:
- 促进更高精度、更低误差;落地与投入的驱动力。
- 单机难以为继 → 分布式训练与集群化。
- 多样数据格式与任务 → 更灵活的框架与编译体系。
- 安全与合规挑战 同步上升。
AI 算法的进步
-
精度超越传统 ML
“MNIST 上 CNN 错误率降至 0.23%(2012),接近人类 0.2%。” -
公开数据集上的持续突破
“Lenet(1998)→ AlexNet(2012,引入 GPU/ ReLU/ Dropout/ LRN)→ Inception(2015)→ ResNet(2015,更深)→ MobileNetV3 + NAS(2019)。”
三类演化:更优激活/层(ReLU/BN)、更深更大网络、更佳训练技巧(正则化/初始化/学习率/AutoML)。
算力与体系结构进步
- “摩尔定律放缓 → 专用芯片 定制化(GPGPU、TPU、NPU、Transformer Engine)。”
- “脉动阵列(Systolic Array)、3D Cube 等设计提升矩阵运算密度与能效。”
- “稀疏/量化 算法特性下沉到硬件,软硬协同显著加速。”
- “单芯片 Scale Up 与集群 Scale Out 并举;并行系统设计 与 作业特征(如稀疏性) 的协同优化成为主线。”
小结与思考
- “三大驱动力:数据规模、计算能力、算法突破。”
- “系统设计需与上层负载同频:在大模型/稀疏/动态/AutoML/强化学习等趋势下,编程表达、编译优化与分布式执行需协同演进。”
- “学习方法—模型结构—硬件体系 彼此牵引;AI 系统的核心挑战在于:性能极致、规模弹性、成本可控与安全合规 的统一。”
AI 系统全栈架构
AI 系统概述
AI 系统基本概念
“AI 时代连接硬件和上层应用的中间层软硬件基础设施。”
- 与“AI Infra”相关,但更强调“让 AI 执行起来的系统体系结构”。
- 传统:数据库/操作系统/中间件抽象硬件复杂性;
云时代:IaaS/PaaS/SaaS;
AI 时代:承担连接算力与应用的基础设施中间层,提供基础模型服务、微调与应用开发。

AI 系统详细定义
“开发者通过 Python 与 AI 框架(PyTorch/MindSpore 等)编码与描述模型、训练与部署流程。”
- 早期 AlexNet 直接用 CUDA;如今**框架 + 生态(HuggingFace/FairSeq/MMDetection/NNI)**提升生产力。
- 不同领域差异(输入/输出/数据获取)→ 定制框架与工具;
主流:PyTorch、TensorFlow、JAX、MindSpore 等,配合社区模型中心与推理工具。 - 硬件演进:GPU/TPU/NPU/张量核/脉动阵列等支撑大规模训练与推理。

AI 系统设计目标
- 高效编程语言、框架与工具链
“更强表达能力与更简洁原语;屏蔽底层细节;调试/可观测/扩展完善。”
- 支持全生命周期:数据处理、训练、压缩、推理、安全与隐私。
- 任务级系统支持
“支持强化学习、AutoML 等新范式;可扩展计算能力(并行/分布式/集群);自动编译优化(推导/并行化/JIT);云原生自动分布式化。”
- 面向新挑战的设计与演化
“动态图/动态 Shape、稀疏与混合精度、混合训练范式、多任务编排;企业级多租与跨端推理;安全与隐私。”
AI 系统组成
“大致分为若干方向(训练与推理框架、编译与计算架构、硬件与体系结构等)。”
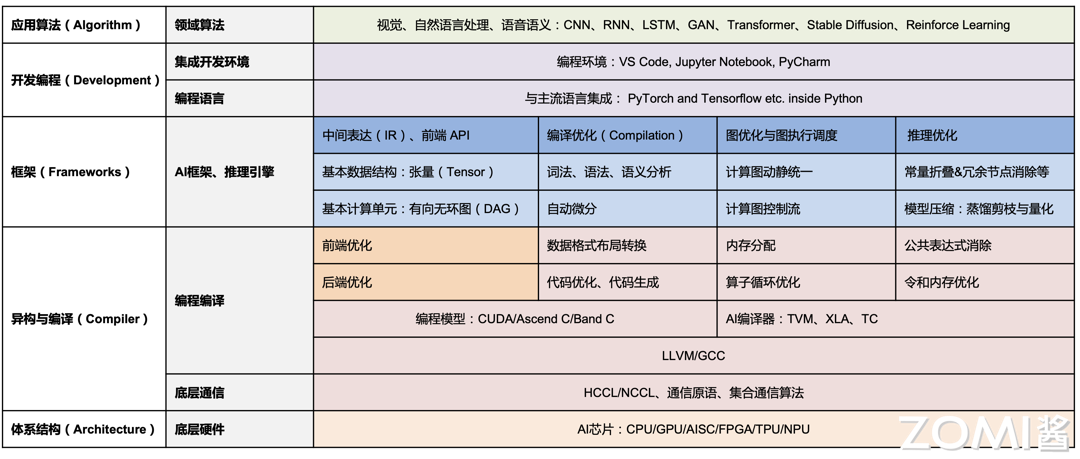
AI 训练与推理框架
“提供前端编程接口与工具链;静态分析与计算图构建、编译优化。”
- 网络模型构建:CNN/RNN/Transformer 与控制流/API。
- 模型算法实现:训练/推理、监督/无监督/强化等流程。
- 计算图:静态与动态图(PyTorch 2.x 引入 Dynamo 走向融合)。
- 自动求导:算子级封装 + 全图自动微分。
- 多层 IR:为后端编译优化铺路。
- 流水线/工作流 与工具链:迁移、转换、调试、可视化、类型系统等。
- 生命周期管理(MLOps):数据/训练/推理流程化与模块化。
AI 编译与计算架构
“为多硬件平台提供迁移性与高性能:ONNX 等中间格式 + TVM/Glow/XLA/Jittor 等编译器。”
-
特征:
- 主前端语言多为 Python/AST→图 IR(保留 shape/layout)。
- 多层 IR:兼顾易用与性能;算子抽象 vs. 循环级优化。
- 面向 NN 的张量类型/自动微分。
- DSA 芯片中心(GPU/NPU/TPU 等)。
-
关键能力:
- 编译优化:算子融合、循环/布局优化、等价/近似图变换。
- JIT/自适应优化:运行期根据硬件与数据分布自调优。
- 调度与执行:算子级并行、线程策略、资源复用。
- 硬件抽象:统一接口屏蔽 GPU/NPU/TPU/CPU/FPGA/ASIC 差异。
AI 硬件与体系结构
“程序真正执行、互联与加速;平台侧做调度、资源分配与隔离。”
- 资源池化与调度:异构集群、拓扑感知。
- 高性能互联:RDMA/InfiniBand、NVLink/NVSwitch、AllReduce/通信聚合。
注:后续章节将聚焦训练/推理框架、编译器与芯片,必要处延伸到平台与生态。
AI 系统生态
“除核心构成外,还包含平台调度、算法与框架演进、安全与隐私、部署与优化等更广泛内容。”
核心系统软硬件
- 运行与优化环境:算子/任务调度、内存/I-O 管理、未来的多路复用。
- 通用资源调度:多租公平/效率/稳定。
- 新型硬件 + 高性能网络栈:灵活适配,静/动态结合优化,前瞻瓶颈与机会。
AI 算法和框架
- 通用高效算法:新算子/灵活结构/融合(如 MoE)。
- 多框架统一支持:提升体验与复用。
- 神经网络编译优化:静态分析 + 融合/循环级优化 + 图等价变换。
更广泛生态
- 强化学习:与环境交互的数据路径 → 新的训练范式支持。
- AutoML(HPO/NAS):大搜索空间 → 多任务调度与编排。
- 安全与隐私:数据与模型双重维度。
- 推理/压缩/优化:前向为主、更低时延与资源约束、量化/蒸馏/剪枝等。
小结与思考
- “AI 系统=连接硬件与应用的基础设施,涵盖语言/框架/编译/硬件/平台等多层。”
- “设计目标:高效表达+系统级支持+面向新挑战演进(动态图/稀疏/多任务/多租/跨端/安全)。”
- “组成:框架→编译→硬件,并延展到生态(调度、AutoML、推理优化、安全隐私)。”
- “经典系统理念(OS/编译器/分布式/云原生)在 AI 场景中依旧适用并持续演化。”
AI 系统与程序代码关系
以 PyTorch 实现 LeNet-5 为例,把上层 Python 代码与底层 AI 系统各层的运行机制建立桥梁,并标注关键系统问题与思考。
神经网络样例
AI 训练流程原理
“前向传播(Forward)产生输出;训练是一个最小化损失的优化问题:
(\theta = \arg\min_\theta \sum \mathrm{Loss}(f_\theta(x),y)),
用梯度下降 (\theta \leftarrow \theta - \alpha \nabla_\theta \mathrm{Loss})。”
- 推理(Inference):仅执行前向传播 (\hat y = f_\theta(x))。
- 特征图(Feature Map):各层输出在计算图中对应具体算子序列。
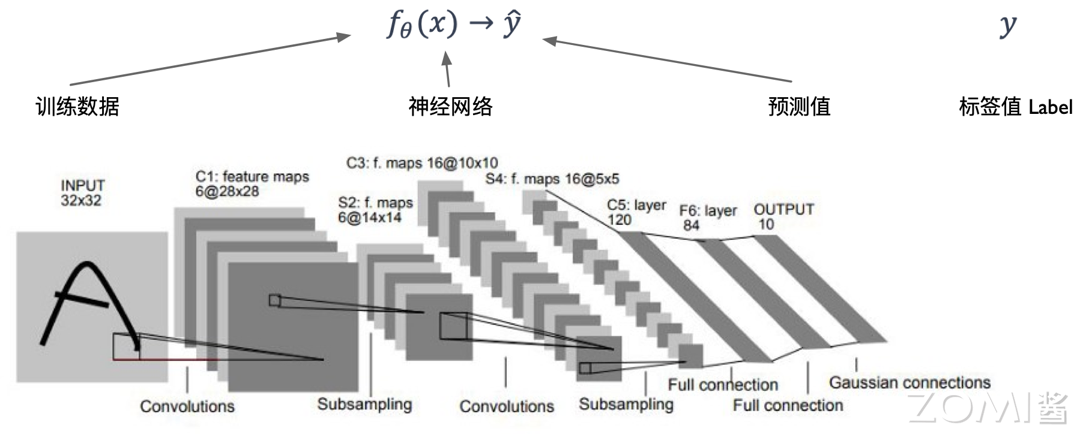
术语:“算子(Operator, Op) 是张量计算基本单元;底层实现为 Kernel(常映射到 GEMM/卷积等),再被翻译为 循环(Loops)与指令。”
网络模型构建
“两阶段:1)定义网络结构(Conv/Pool/FC 等);2)开始训练(批处理→前向→Loss→反向→更新)。”
- PyTorch 训练流程:
DataLoader → model(x) → loss → backward → step。 - 设备选择与内存/并行:
device = torch.device("npu"|"gpu"|"cpu");若模型/激活过大,需模型并行/数据并行与分布式训练。
算子实现的系统问题
卷积实现原理
“滑动窗口与卷积核做矩阵内积(Dot Product),加偏置后输出到特征图。”
- 形状示例:输入 (3\times32\times32) 经 (2\times3\times5\times5) 卷积 → 输出 (2\times28\times28)。
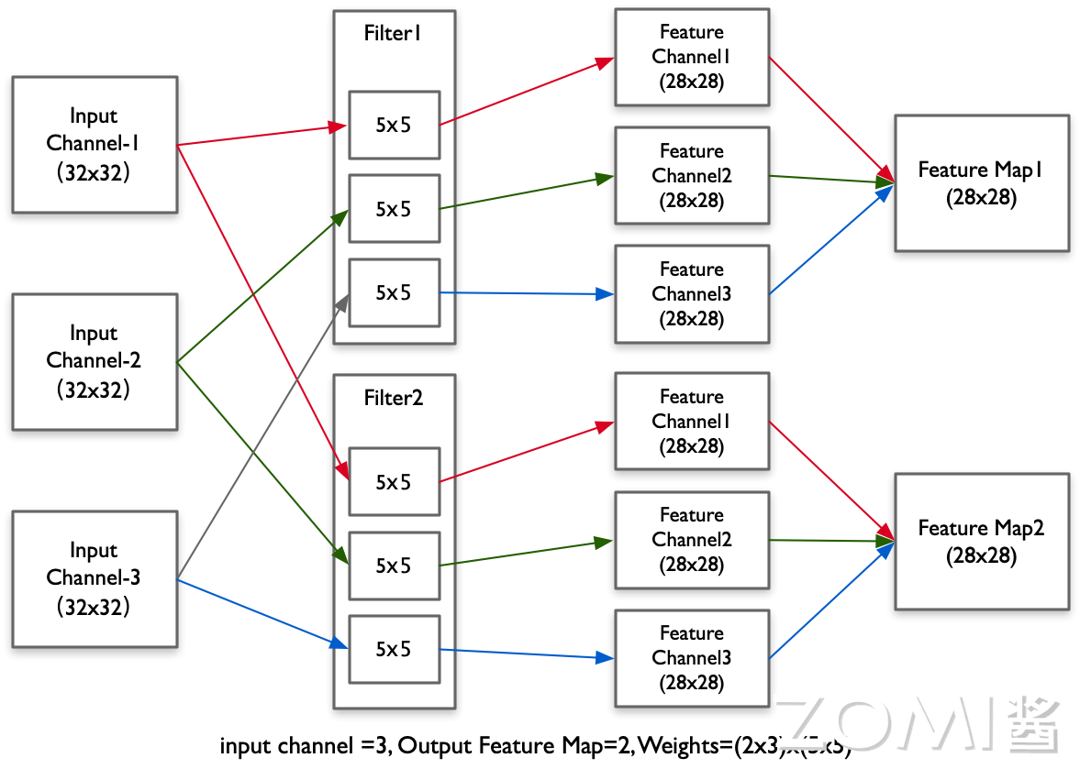
卷积执行样例
“Conv2D 可被展开为 7 重循环(n/oc/ic/h/w/fh/fw)做乘加(MAC)。”
- 直观代码:多层 for-loop(批、通道、高宽、核高宽)→
output += input * kernel。 - 要点:这类循环是编译器与硬件优化(循环切分/重排/向量化/并行)的直接入口。
AI 系统遇到的问题(面向实现的发问)
- 硬件加速:矩阵乘/GEMM 是主力;NPU/GPU/TPU(脉动阵列)如何专用加速?
- 片上存储:输入/权重/输出能否装入 L1/L2/共享内存?→ Tile/切片策略。
- 局部性:空间/时间局部性能否通过循环变换榨干缓存/带宽?
- 内存与扩展:按层估算张量占用,设计内存复用/溢出到 HBM/Host与换入换出策略。
- 运行时调度:算子间依赖与并行如何在 Runtime 高效调度?
- 算法变换:能否把循环型卷积改写为 im2col+GEMM 等更易优化形式?
- 编程方式:在灵活表达与高效执行间,如何用框架/IR/JIT 取得平衡?
AI 系统执行具体计算
“上层仅需 Python + 框架 API;底层通过算子库(cuDNN/cuBLAS 等)与编译/运行时完成 Kernel 执行。”
-
没有框架会怎样?
用 CUDA + cuDNN 写 LeNet 需 上千行:手工内存分配/释放、前反向每层 API 调用、权重更新、图拼接等。

-
有框架有什么不同?
用 PyTorch 写 LeNet 结构仅 十余行:- Python API 构图(前向即图);
- 封装算子(极大减码);
- 自动内存与生命周期管理;
- 自动微分(自动构建反向图);
- 调用/生成优化代码,在 NPU/GPU 调度算子;
- 运行期并行与自适应优化(提升加速器利用率)。
结论:框架/编译器/算子库 是算法生产力倍增器;隐藏复杂性的同时也形成系统工程的主战场(IR 设计、调度、存储层次、并行与通信、跨设备/多租支持等)。
小结与讨论
- “多层抽象让日常实践难以直观看到底层机制,但理解系统细节能反过来指导更高效的作业与代码。”
- “AI 系统承担了表达→编译→运行全链路:从 Python 图到 IR/Kernel,再到设备执行与分布式调度。”
- “要写好上层 AI 代码,也要理解底层在做什么:内存/带宽/并行/通信决定了最终性能与可扩展性。”



