读 ncnn 源码(Ⅱ):层工厂与“覆盖机制”,以及 CPU 端的指令集优选
延续前文对 Net::load_param 的解析,这一篇聚焦两件事:
① ncnn 如何把 字符串层名 映射到 内置层 并允许你覆盖默认实现;
② CPU 端如何在运行时按 AVX512/FMA/AVX/… 等指令集优选最快实现,并且逐层回退兜底。
TL;DR
layer_registry[] 是内置层名册:把 "Convolution" 这类字符串类型映射到typeindex,并关联一个 creator(工厂函数指针)。create_overwrite_builtin_layer(...) 让你按 typeindex 覆盖内置实现(优先级最高,早于 Vulkan/CPU 路径)。create_layer_cpu(...) 会在运行时检测 CPU 能力,从高到低选择 AVX512 → FMA → AVX → LASX → LSX → MSA → XTheadVector → RVV → arch 基线;若该 ISA 下此层没特化实现,自动回退到更通用实现。Net::load_param 的创建优先级:Overwrite → Vulkan → CPU(按 ISA 优选) → Custom。- 实战:通过覆盖机制可“接管”内置层(加日志/替换 kernel),通过自定义机制可新增算子名。
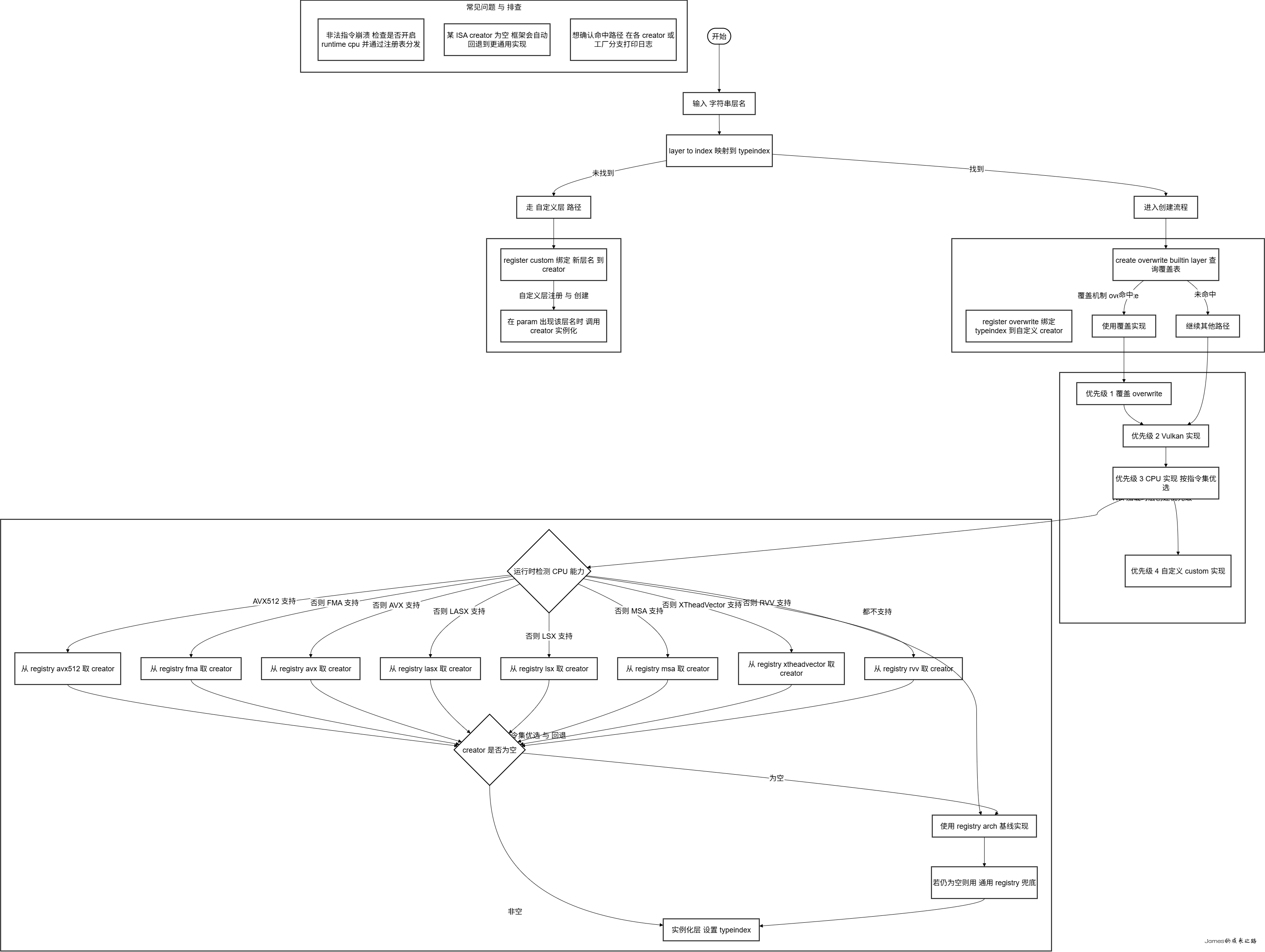
1) 从层名到内置层:layer_to_index 与 layer_registry
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| struct layer_registry_entry
{
#if NCNN_STRING
const char* name; // 层类型名(字符串)
#endif
layer_creator_func creator; // 工厂函数指针:Layer* (*)(void*)
};
static const layer_registry_entry layer_registry[] = {
#if NCNN_STRING
{"AbsVal", AbsVal_layer_creator},
#else
{AbsVal_layer_creator},
#endif
{"ArgMax", 0}, // 该层在此构建里没有默认 creator,留待回退或自定义
// ...
};
int layer_to_index(const char* type)
{
for (int i = 0; i < layer_registry_entry_count; i++)
if (strcmp(type, layer_registry[i].name) == 0)
return i;
return -1; // 非内置层名
}
|
layer_registry[] 是静态注册表:维护内置层名 → creator 的映射。{"ArgMax", 0} 这种creator 为空的条目意味着:当前构建没编进该层的默认实现(或被裁掉)。加载时会走回退/自定义路径。- 受
NCNN_STRING 控制:关闭后不保留字符串名,部署走二进制 param。
2) 覆盖内置层:create_overwrite_builtin_layer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| Layer* Net::create_overwrite_builtin_layer(const char* type)
{
int typeindex = layer_to_index(type);
if (typeindex == -1) return 0;
return create_overwrite_builtin_layer(typeindex);
}
Layer* Net::create_overwrite_builtin_layer(int typeindex)
{
// 在 Net 实例私有的覆盖表中查找
for (auto& e : d->overwrite_builtin_layer_registry)
if (e.typeindex == typeindex && e.creator)
{
Layer* L = e.creator(e.userdata);
L->typeindex = typeindex;
return L;
}
return 0; // 无覆盖项
}
|
- 你可以把已有内置层(如
"Convolution")换成自己的实现(加日志/计时/特化 kernel)。
- 覆盖表绑定的是 typeindex(不是字符串),因此只对内置层有效。
- 在
Net::load_param 的创建顺序里,覆盖实现的优先级最高——先尝试它,失败再走 Vulkan/CPU/自定义。
最小覆盖示例(示意):
1
2
3
4
5
6
| // 1) 自己的 creator
static Layer* MyConvCreator(void* ud) { return new MyConvWrapper(/*ud*/); }
// 2) 注册覆盖(伪 API,按你工程里的 Net 扩展接口调用)
net.register_overwrite_builtin_layer(layer_to_index("Convolution"),
MyConvCreator, my_userdata);
|
3) CPU 端:按指令集优选、逐层回退的工厂
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| Layer* create_layer_cpu(const char* type)
{
int index = layer_to_index(type);
if (index == -1) return 0;
return create_layer_cpu(index);
}
Layer* create_layer_cpu(int index)
{
layer_creator_func creator = nullptr;
#if NCNN_RUNTIME_CPU && NCNN_AVX512
if (ncnn::cpu_support_x86_avx512())
creator = layer_registry_avx512[index].creator;
else
#endif
#if NCNN_RUNTIME_CPU && NCNN_FMA
if (ncnn::cpu_support_x86_fma())
creator = layer_registry_fma[index].creator;
else
#endif
#if NCNN_RUNTIME_CPU && NCNN_AVX
if (ncnn::cpu_support_x86_avx())
creator = layer_registry_avx[index].creator;
else
#endif
#if NCNN_RUNTIME_CPU && NCNN_LASX
if (ncnn::cpu_support_loongarch_lasx())
creator = layer_registry_lasx[index].creator;
else
#endif
#if NCNN_RUNTIME_CPU && NCNN_LSX
if (ncnn::cpu_support_loongarch_lsx())
creator = layer_registry_lsx[index].creator;
else
#endif
#if NCNN_RUNTIME_CPU && NCNN_MSA
if (ncnn::cpu_support_mips_msa())
creator = layer_registry_msa[index].creator;
else
#endif
#if NCNN_RUNTIME_CPU && NCNN_XTHEADVECTOR
if (ncnn::cpu_support_riscv_xtheadvector())
creator = layer_registry_xtheadvector[index].creator;
else
#endif
#if NCNN_RUNTIME_CPU && NCNN_RVV
if (ncnn::cpu_support_riscv_v())
creator = layer_registry_rvv[index].creator;
else
#endif
{
creator = layer_registry_arch[index].creator; // 本架构“基线”实现
}
if (!creator)
creator = layer_registry[index].creator; // 平台无关通用兜底
if (!creator) return 0;
Layer* L = creator(/*userdata=*/0);
L->typeindex = index;
return L;
}
|
关键信息:
- 打开
NCNN_RUNTIME_CPU 时,ncnn 会在运行时做能力检测(CPUID/特征寄存器),确保不会执行超过当前 CPU 能力的指令。
- 每个 ISA(如 AVX512/FMA/AVX/…)都有一套特化注册表
layer_registry_xxx[];若该 ISA 下此层没有实现(creator 为 0),就回退到更通用表。
- 回退链末端是:本架构基线(
layer_registry_arch)→ 平台无关通用实现(layer_registry)。
例子:你看到 layer_registry_fma[] 里是 {"ArgMax", 0},说明 FMA 路径没有 ArgMax 特化实现,本层会自动回退到 arch 基线或通用实现,无需手工干预。
4) 大图回看:层创建的全局优先级
在 Net::load_param(...) 的创建顺序为:
- Overwrite:
create_overwrite_builtin_layer(type)(有你注册的覆盖就优先用)
- Vulkan:
create_layer_vulkan(type)(启用且设备/层支持)
- CPU:
create_layer_cpu(type)(本篇这套 ISA 优选 + 回退)
- Custom:
create_custom_layer(type)(新增的层名才会走这里)
这保证了:
- 你可以插队接管内置层(做日志/特化)。
- 在 GPU 不可用或不适配时,自动回退到最快的 CPU 实现。
- 新增的非内置层名也能被识别和实例化。
5) 常见问题与排查建议
- “非法指令”崩溃?
检查是否 关闭了 NCNN_RUNTIME_CPU 却静态链接了高 ISA 对象并直接调用。正确姿势是只通过注册表拿函数指针,并依赖运行时检测。
- 某层在某 ISA 下 creator 为 0
正常。框架会回退到更通用实现;你也可以通过覆盖机制为它补特化实现。
- 覆盖与自定义的边界
覆盖(overwrite)只针对内置层(按 typeindex);自定义(custom)只处理非内置层名(按字符串)。
- 想确认命中了哪条路径
在各 *_layer_creator 或 create_layer_cpu() 命中分支打印一行日志即可(开发期很实用)。
6) 实战:两种注册套路(示意)
A. 覆盖内置层(替换 Convolution)
1
2
3
4
5
6
| // 覆盖的创建函数
static Layer* MyConvCreator(void* ud) { return new MyConvWrapper(/*ud*/); }
// 注册:把内置 Convolution 的 typeindex 绑定到你的 creator
int idx = layer_to_index("Convolution");
net.register_overwrite_builtin_layer(idx, MyConvCreator, my_userdata);
|
B. 新增自定义层(完全新名字)
1
2
3
4
5
6
7
| // 新层创建函数
static Layer* MyFancyOpCreator(void* ud) { return new MyFancyOp(/*ud*/); }
// 注册:绑定到字符串层名
net.register_custom_layer("MyFancyOp", MyFancyOpCreator, my_userdata);
// .param 里出现 "MyFancyOp ..." 行时即可被创建
|
两者可以并存:已有的内置层用覆盖路径插桩或替换;模型里独有的特殊算子用自定义层补齐。
该封面图片由Ahmet Yüksek在Pixabay上发布